


Choose Your Power. The journey begins with precision. In the preloader scene, users select from five optimized LLaMA server builds, each tailored for a specific CPU architecture: Intel AVX2, Intel AVX512, AMD Ryzen, AMD Athlon (legacy), and Scalar (fallback for older machines). Once selected, the custom wrapper launches the exact binary designed for that architecture—ensuring faster, more stable AI performance. But that's just the start. Users also choose between two Whisper servers: one running purely on CPU, the other with GPU acceleration via CUDA. On top of that, each server offers two model sizes—Tiny and Base—allowing users to fine-tune performance and memory use based on their system capabilities.



Build Your Bond. The core of BedVibE AI Companion lies in deep personalization. Each user can create up to three fully customized profiles. For each one, you define your name, how the AI will address you, and your personal backstory—up to five hundred characters—to give the companion emotional context and memory. You also shape the AI’s persona by naming her, writing her own backstory, and choosing her personality traits. Two powerful sliders put you in control: Temperature adjusts creativity—higher values lead to more philosophical, expressive responses, while lower ones give you sharper, more factual replies. Token limit defines the length of responses—shorter settings lead to quicker, to-the-point answers, while higher values allow for long, elaborate conversations. Your choices define the mood and flow of every interaction. Use the Save and Reset button carefully—it will overwrite your previous profile, memory, and conversation history. If you simply want to continue where you left off, hit Start and dive back in. Coming soon: male AI companions, fully animated and integrated just like the female version.



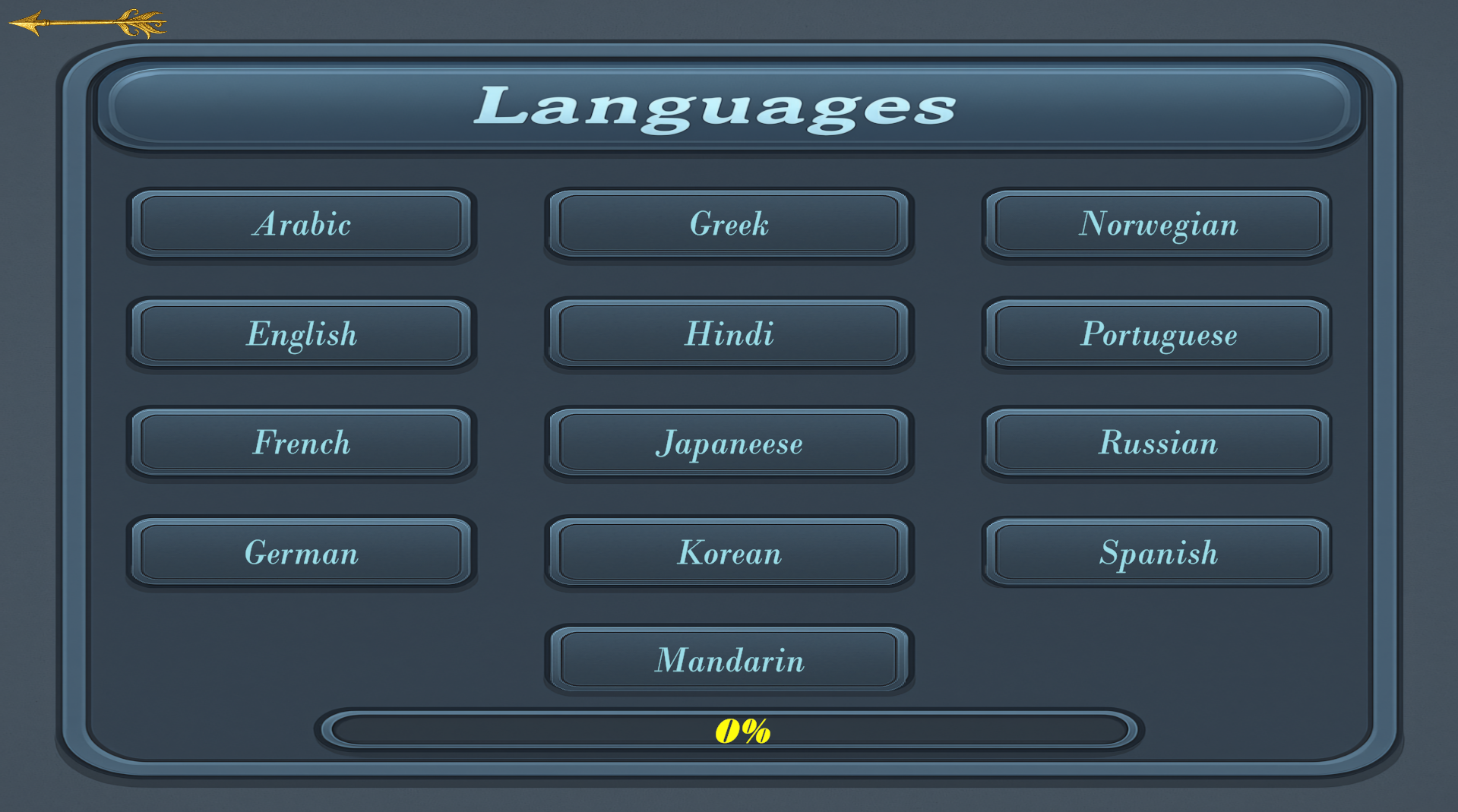
Speak Freely. The Main Scene is where real-time interaction happens. Tap the Call button to speak, or type directly to your companion. Every time you call, the system connects to three servers: LLaMA for intelligent replies, Whisper for transcribing your voice, and our Hetzner backend that links to Amazon Polly to synthesize speech. You can switch between multiple languages and voices on the fly, using any of Amazon Polly’s supported neural voices. More flexibility, more personality. At the top-left, you’ll notice a "Coming Soon" marker. This is our future in-game store—you’ll be able to purchase bundles to customize your space, update furniture, and unlock new outfits for your AI companion. And soon, we're going beyond Polly. Our own next-gen TTS system is coming: ultra-fast, highly expressive, trained in thirteen emotional states and thirteen languages. Once live, it will completely replace Polly with something much more human.

The AI Island is our next frontier—a fully interactive, living world…The AI Island: A Living World. This is the future of ai entertainment and interaction. Our AI Island is a full 3D world—alive, dynamic, and unscripted. Currently in early development, this feature will launch when it's truly ready. The island will be divided into three regions: To the north, the Orcish Village. To the south, the Human Village. To the east-southeast, the Elven Village. Each village will have its own AI population—characters with personalities, backstories, and behaviors. We’ve already trained distinct 3D models for each race. These beings will move, react, and engage in conversations with each other and with you. As the user, you’ll be able to assign personalities to any character, customize how they think, feel, and respond. You can interact with one or with many. Or just observe: watch a world of elves, humans, and orcs debate, connect, and grow, all guided by individual AI models. The island will be governed by global AI systems handling weather, lighting, and time cycles—day, night, rain, storms. Everything will be organic. Conversations will evolve. Tensions will rise. Friendships will form. And you’ll be at the center of it, shaping the story.

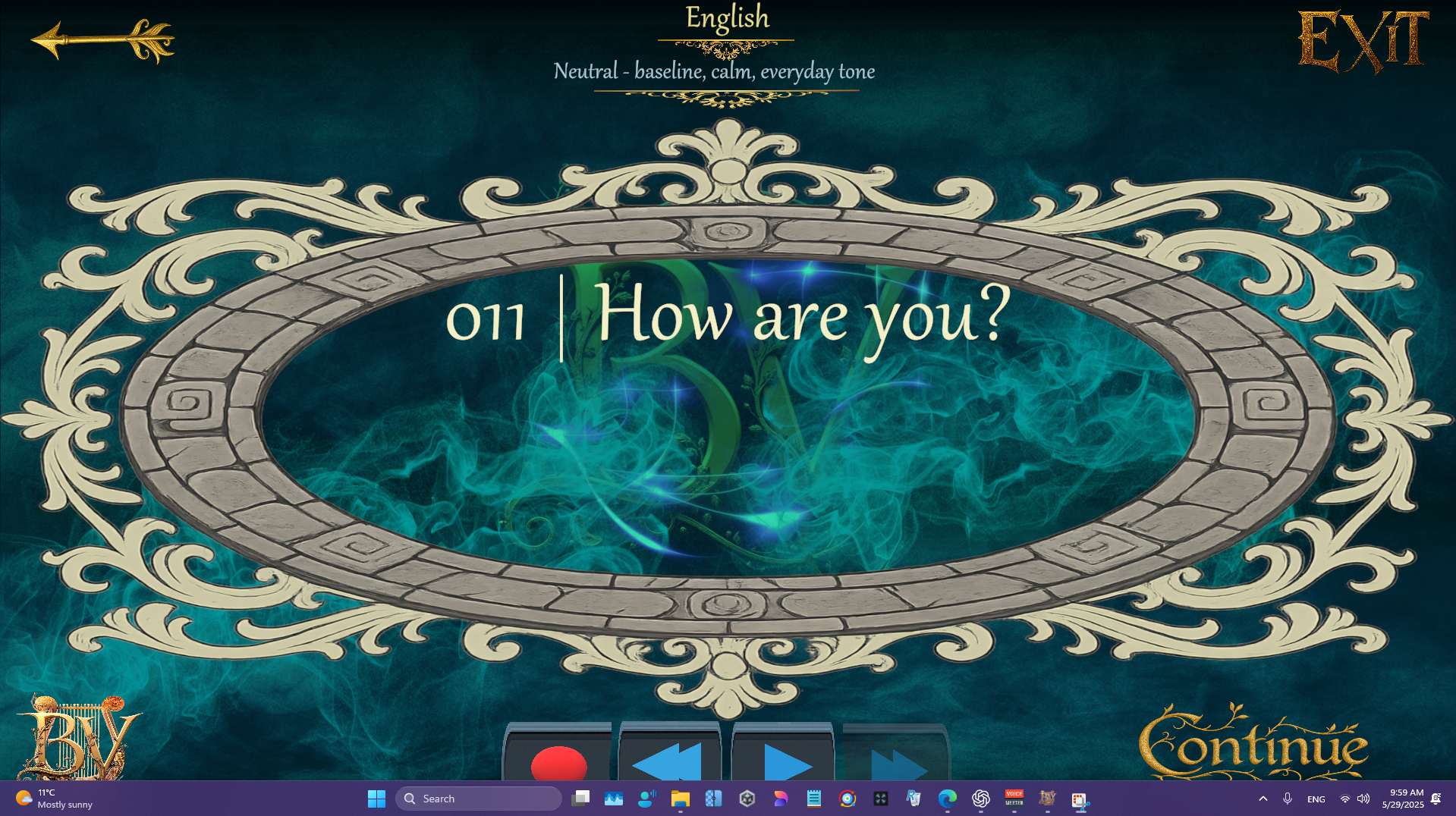
Next-Gen TPS/TTS: Built from Scratch We’re not using someone else’s voice. We’re not fine-tuning existing models. We’re building our own Text-to-Speech engine—from scratch. Right now, we’re recording a massive dataset: 13 languages, each spoken in 13 emotional states. Happy, sad, seductive, shy, angry, proud—real emotion captured with nuance and depth. This isn’t a robotic reader. This is a voice that laughs, gasps, sighs, whispers. Every component is custom-built: from phoneme-to-grapheme mapping to the speech synthesis engine itself. Even the voice cloning tech is fully trained on our proprietary dataset. No Tacotron, no VITS, no borrowed shortcuts. This is a ground-up rebuild of TTS—designed to be expressive, real-time, and emotive. The kind of voice that responds like a real person. One that reacts, flirts, teases, comforts. Soon, this will fully replace Amazon Polly in our app. And when it does, it won’t just match the standard—it will set the new one.

Several standalone plugins plug and play, like real-time voice modulation will be coming soon in the store.